Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- STMicroelectronics Community
- Product forums
- Edge AI
- Re: How to deploy a quantized model on an embedded...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to deploy a quantized model on an embedded platform
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
2024-02-08 11:51 AM
Hello everyone,
I have a pytorch model (mymodel.pth) obtained by running the mixed-precision quantization of this algorithm: * https://github.com/eml-eda/q-ppg. I followed the instructions in the readme section.
Python models are not natively supported by X-CUBE-AI so I convert mymodel.pth to ONNX.
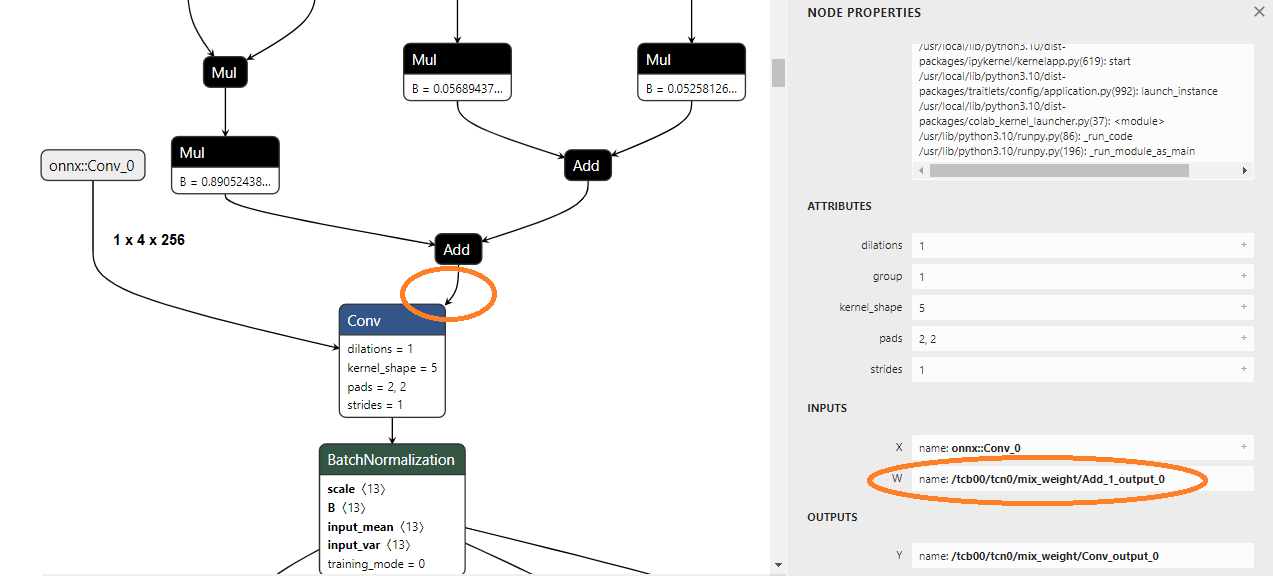
But if I open mymodel.onnx with Netron, I can see that each convolutional layer has 2 inputs (see image) and STM32CubeIDE doesnt' support this.
* Reading the paper, I know that the quantized model obtained by Q-PPG has been deployed on STM32WB55. So how can I deploy the model on the embedded platform?
I use Windows 10 Home 64 bit (10.0, build 19045), STM32CubeIDE 1.13.1 and X-Cube-AI 8.1.0 (I've also tried 8.0.1).
Could anyone please help me?
Labels:
- Labels:
-
STM32 ML & AI
-
STM32CubeAI
-
STM32CubeMX
{kind=link}
1 REPLY 1
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
2024-02-09 12:06 AM
in STM32Cube.AI for quantized ONNX networks we support the QDQ format.
The current recommended flow is to export the pytorch float model to ONNX and then use the ONNX Runtime post training quantization to quantize the model.
You can refer to the embedded documentation for details on how to perform quantization and the supported parameters
Generally the packs are located in your home and this chapter is located here:
~/STM32Cube/Repository/Packs/STMicroelectronics/X-CUBE-AI/8.1.0/Documentation/quantization.html
Regards
Daniel
In order to give better visibility on the answered topics, please click on 'Accept as Solution' on the reply which solved your issue or answered your question.
In order to give better visibility on the answered topics, please click on 'Accept as Solution' on the reply which solved your issue or answered your question.
Related Content
- OPTEE 4.0.0-stm32mp-r1 compilation and and CFG_DRAM_SIZE issue in STM32 MPUs Products
- CubeMX generated code error when using BSP code in STM32CubeIDE (MCUs)
- SensorTile(STEVAL-STLKT01): Cannot build example project FP-SNS-ALLMEMS1 for project "STM32L476JG-SensorTile" in MEMS (sensors)
- EMMC Device Tree Path Not Found during U-Boot in STM32 MPUs Embedded software and solutions
- STM32Cubeprogrammer download failed in STM32 MPUs Products