
STLINK-V3MINIE - Feature: Pipelined Data Transfers
@ ST engineers: This is a feature request for the firmware of the STLINK-V3MINIE and related debuggers/programmers: pipelined data transfers over the existing USB High-Speed link.
In my pursuit to greatly improve the STLINK-V3MINIE's performance for large continuous reads from MCU memory, I discovered there is huge room for improvement: SWD's full potential (~2038 KB/s = 24M [cycles/s] * 4 [bytes/transfer] / (46 [cycles/transfer])) is not yet used at all. (Note that USB shouldn't be the bottleneck, judging from the maximum clock speed the STLINK-V3MINIE's STM32F723's USB IP can support.) I only achieve ~549 KB/s when using an STM32H7S3 MCU with ST's programming SW (v2.20.0) using STLINK-V3MINIE (FW V3J17M10):
STM32_Programmer_CLI --connect port=SWD freq=24000 ap=1 mode=HOTPLUG -halt --read 0x24000000 0x60000 /tmp/dmp.binA simplified sequence diagram of the communication used here is shown:
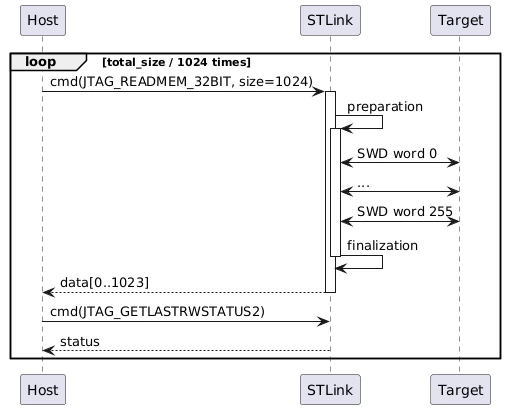
I measured the SWD clock line with an oscilloscope to verify 24 Mhz is reached, and I can confirm this is the case, so SWD should only take ~491 us (= 1 KB / ~2038 [KB/s]).
But when looking at the USB timings, the time from JTAG_READMEM_32BIT command to 1024-byte data arrival is ~1642 us (of which only ~40 us for the sending of the command). So it seems like most of the time (~1111 us = ~1642 us - ~40 us - ~491 us) is not usefully spent, considering the USB data rate is much faster than the SWD data rate.
In order to improve performance, I tried dividing the buffer read into bigger chunks (6144 instead of 1024 bytes) and leaving out the status queries:
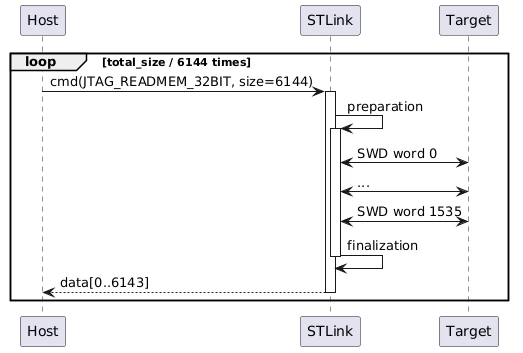
and this did improve performance a bit (~633 instead of ~549 KB/s), but there still seems to be a lot of time uselessly spent: the time from JTAG_READMEM_32BIT command to 6144-byte data arrival is ~9340 us (of which only ~40 us for the sending of the command), which is again much higher than the time SWD communication should take: ~2944 us (= 6144 bytes / ~2038 [KB/s]).
Therefore I wanted to go one step further, and enable pipelined transfers: queue multiple concurrent read requests such that all the time that was previously spend doing stuff other than SWD communication (i.e., preparation, USB communication, and finalization) can be done in parallel with SWD communication. I figured two concurrent read requests would be a good starting point. Here is how the communication would look like:
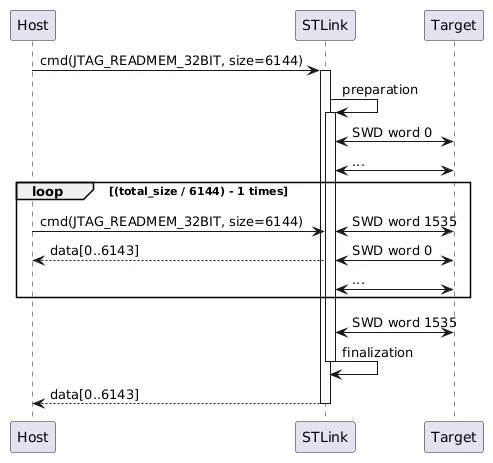
When I tested this, after having sent two commands, reading the data timed out. Likely this is because the STLINK-V3MINIE's firmware doesn't support two concurrent read requests. It seems like the firmware is protected with an authentication header, so I wasn't able to easily patch the firmware for this new feature. Therefore I would like to ask ST whether they can implement such feature?
Thanks a lot!